Deep Neural Networks
Jan 1, 2023
TrungTin Nguyen
Postdoctoral Research Fellow
A central theme of my research is data science at the intersection of statistical learning, machine learning and optimization.
Publications
LoGra-Med: Long Context Multi-Graph Alignment for Medical Vision-Language Model
State-of-the-art medical multi-modal large language models (med-MLLM), like LLaVA-Med or BioMedGPT, leverage instruction-following data …
Duy M. H. Nguyen, Nghiem T. Diep, Trung Q. Nguyen, Hoang-Bao Le, Tai Nguyen, An T. Le, Tien Nguyen, TrungTin Nguyen, Nhat Ho, Pengtao Xie, Roger Wattenhofer, James Zhou, Daniel Sonntag, Mathias Niepert
Accelerating Transformers with Spectrum-Preserving Token Merging
Increasing the throughput of the Transformer architecture, a foundational component used in numerous state-of-the-art models for vision …
Hoai-Chau Tran, Duy M. H. Nguyen, Duy M. Nguyen, TrungTin Nguyen, Ngan Le, Pengtao Xie, Daniel Sonntag, James Y. Zou, Binh T. Nguyen, Mathias Niepert
Structure-Aware E(3)-Invariant Molecular Conformer Aggregation Networks
A molecule’s 2D representation consists of its atoms, their attributes, and the molecule’s covalent bonds. A 3D (geometric) …
Duy M. H. Nguyen, Nina Lukashina, Tai Nguyen, An T. Le, TrungTin Nguyen, Nhat Ho, Jan Peters, Daniel Sonntag, Viktor Zaverkin, Mathias Niepert
CompeteSMoE--Effective Training of Sparse Mixture of Experts via Competition
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the …
Quang Pham, Truong Giang Do, Huy Nguyen, TrungTin Nguyen, Chenghao Liu, Mina Sartipi, Binh T. Nguyen, Savitha Ramasamy, Xiaoli Li, Steven Hoi, Nhat Ho
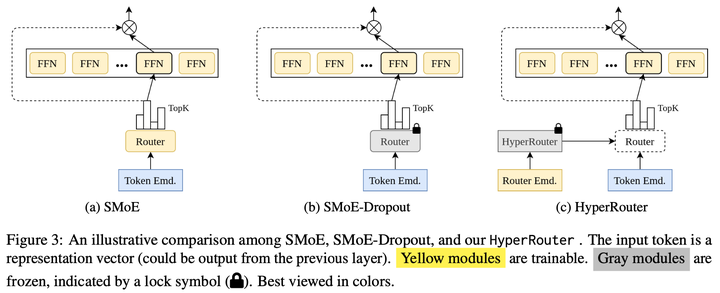
HyperRouter: Towards Efficient Training and Inference of Sparse Mixture of Experts
By routing input tokens to only a few split experts, Sparse Mixture-of-Experts has enabled efficient training of large language models. …
Truong Giang Do, Huy Khiem Le, Quang Pham, TrungTin Nguyen, Binh T. Nguyen, Thanh-Nam Doan, Chenghao Liu, Savitha Ramasamy, Xiaoli Li, Steven HOI